Photos | White-Haired Woman in the Crowd
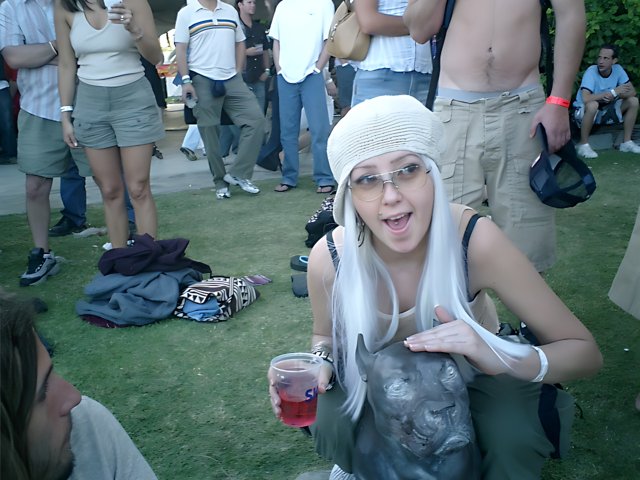
This portrait captures a woman with white hair in the lively crowd during Coachella Day 2 artist area in 2003, holding a cup and wearing a hat and jeans.
BLIP-2 Description:
a woman with white hairChronologically Adjacent


Note: You can also navigate with your arrow keys or swiping.
Metadata
Capture date:
Original Dimensions:
640w x 480h - (download 4k)
{kind=link}
Usage
Dominant Color:
bracelet beer costume summer headgear jeans pants tableware bride necklace glass optical plant artist leisure portrait footwear cap beverage yard wedding outdoors lady luggage hat wristwatch liquor equipment area outdoor utensil baseball cap activities container bag shoe land fun alcohol shirt glasses picnic coachella shorts nature sunglasses electronics backpack grass jewelry skirt backyard accessories blouse handbag home cocktail phone photography laughing dress happy decor cup lawn crowd linen park
metering mode
5
aperture
f/2.5
focal length
6mm
shutter speed
1/80s
camera make
CASIO COMPUTER CO.,LTD.
camera model
date
2002-12-01T01:59:01-08:00
tzoffset
-28800
tzname
America/Los_Angeles
overall
(31.49%)
curation
(50.00%)
highlight visibility
(4.51%)
behavioral
(90.82%)
failure
(-0.32%)
harmonious color
(1.67%)
immersiveness
(0.17%)
interaction
(1.00%)
interesting subject
(-25.73%)
intrusive object presence
(-21.48%)
lively color
(-12.33%)
low light
(11.43%)
noise
(-3.34%)
pleasant camera tilt
(-5.20%)
pleasant composition
(-86.96%)
pleasant lighting
(-14.87%)
pleasant pattern
(0.78%)
pleasant perspective
(-3.79%)
pleasant post processing
(-0.28%)
pleasant reflection
(0.60%)
pleasant symmetry
(0.15%)
sharply focused subject
(1.20%)
tastefully blurred
(-10.47%)
well chosen subject
(-45.34%)
well framed subject
(-8.70%)
well timed shot
(4.93%)
all
(-6.53%)
* NOTE: This image was scaled up from its original size using an AI model called GFP-GAN (Generative Facial Prior), which is a
Generative adversartial network that can be used to repair (or upscale in this case) photos, sometimes the results are a little...
weird.
* WARNING: The title and caption of this image were generated by an AI LLM (gpt-3.5-turbo-0301
from
OpenAI)
based on a
BLIP-2 image-to-text labeling, tags,
location,
people
and album metadata from the image and are
potentially inaccurate, often hilariously so. If you'd like me to adjust anything,
just reach out.