Photos | Reception Room Gathering

Ruth Henig and Baroness Henig join five other individuals in a reception room surrounded by flower arrangements, elegant furniture, and a dining table.
BLIP-2 Description:
a group of people standing around a tableChronologically Adjacent


Note: You can also navigate with your arrow keys or swiping.
Metadata
Capture date:
Original Dimensions:
4368w x 2912h - (download 4k)
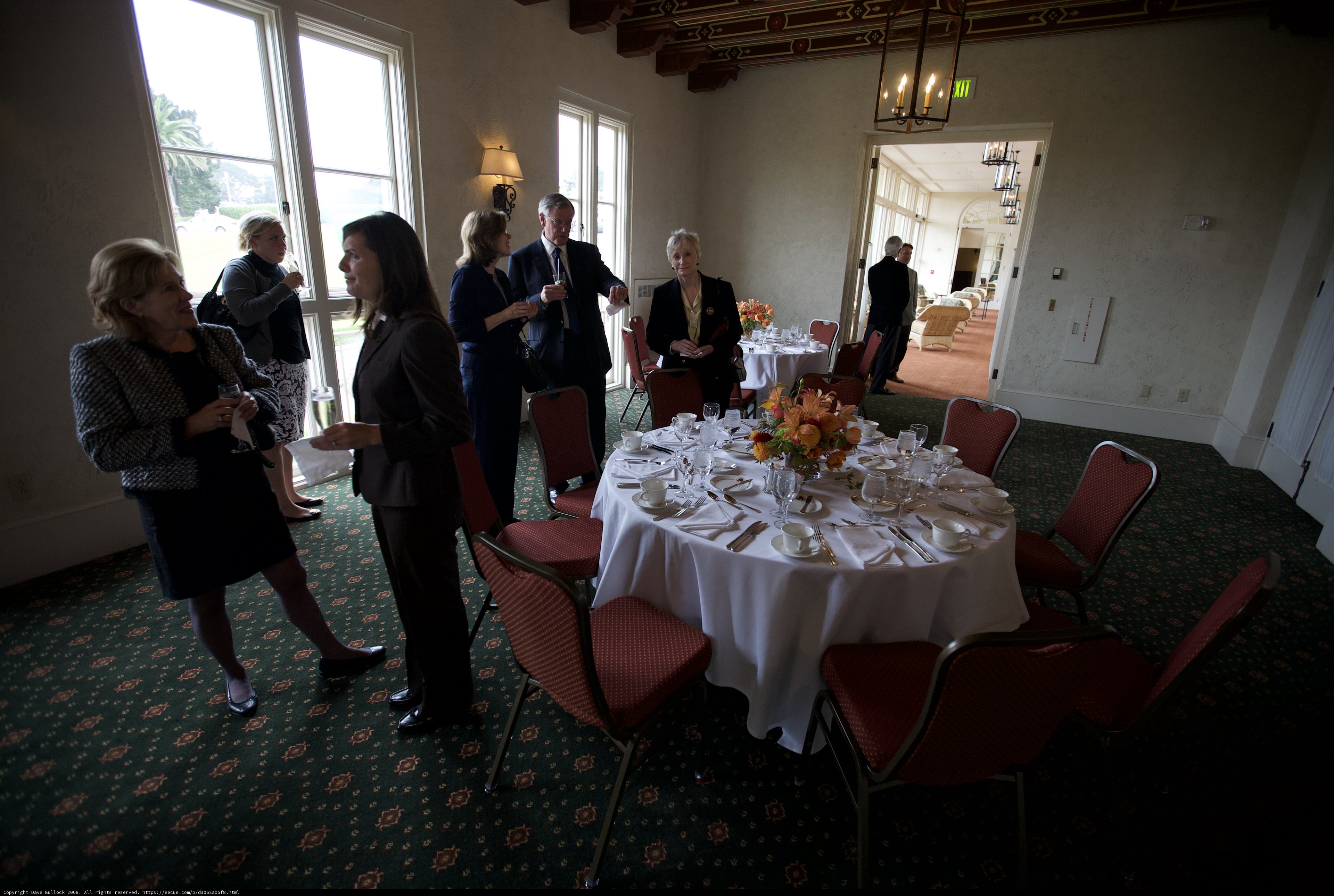{kind=link}
Usage
Dominant Color:
architecture reception tie g door cafeteria formal necklace evening plant building meal henig overcoat window flower footwear chair tuxedo food arrangement lamp transportation wristwatch ruth waiting tablecloth restaurant furniture mike flooring court wood shoe bag reception room knife fashion weapon coat glasses indoors dining interior wear rekognition_c car vehicle jewelry table suit room accessories blade couch baroness home grandma plate chandelier decor sword dress cup floor bouquet handbag linen funeral
iso
800
metering mode
5
aperture
f/2.8
focal length
16mm
shutter speed
1/500s
camera make
Canon
camera model
lens model
date
2008-09-07T12:01:21-07:00
tzoffset
-25200
tzname
America/Los_Angeles
overall
(37.99%)
curation
(65.69%)
highlight visibility
(5.55%)
behavioral
(70.64%)
failure
(-0.39%)
harmonious color
(3.20%)
immersiveness
(0.42%)
interaction
(1.00%)
interesting subject
(-16.25%)
intrusive object presence
(-5.18%)
lively color
(-11.98%)
low light
(97.51%)
noise
(-3.05%)
pleasant camera tilt
(-10.10%)
pleasant composition
(-58.50%)
pleasant lighting
(-57.47%)
pleasant pattern
(14.28%)
pleasant perspective
(-0.24%)
pleasant post processing
(0.93%)
pleasant reflection
(2.15%)
pleasant symmetry
(0.59%)
sharply focused subject
(0.32%)
tastefully blurred
(-9.18%)
well chosen subject
(-23.07%)
well framed subject
(-26.93%)
well timed shot
(-0.63%)
all
(-6.30%)
* NOTE: Amazon Rekognition
detected a celebrity in this image using the
Celebrity Recognition API. The API isn't perfect, but it does give you the MatchConfidence which I display
next to the celebrity's name along with links _↗ to their info.
* WARNING: The title and caption of this image were generated by an AI LLM (gpt-3.5-turbo-0301
from
OpenAI)
based on a
BLIP-2 image-to-text labeling, tags,
location,
people
and album metadata from the image and are
potentially inaccurate, often hilariously so. If you'd like me to adjust anything,
just reach out.